Cross-account access with AWS
Samantha G. Zeitlin
The scene:
I needed to process data from an s3 bucket using pyspark. The s3 bucket was owned by a different account. I had done this before. But this time, there was a twist: we needed to encrypt the data because of GDPR requirements. At the end of the processing, I needed to save the results to another s3 bucket for loading into Redshift.
Thus began a weeks-long saga of learning about AWS the hard way.
(Disclaimer: I am not a devops person. I’ve learned about infrastructure only because I wanted to be able to handle my own data pipelining.)
The first thing you need to know about AWS, which I had never realized before really being forced to understand how it all works, is that everything in AWS makes more sense if you think about it from the perspective of security requirements. It doesn’t make sense if you think about how you would use the services. It’s not set up to be easy to use. It’s set up to be so secure it’s almost unusable.
With that in mind, here’s some background information, before I get into the stuff I learned the hard way.
AWS Services used:
-
S3: Simple Storage Service, where the input data and scripts are stored, and where the results will be saved
-
IAM: Identity and Access Management, the role management service that controls access for users and services
-
KMS: Key Management Service, which controls encryption and access to the s3 bucket
-
EC2: Elastic Cloud Compute, the AWS hosted machines that form the EMR cluster
-
EMR: Elastic Map Reduce, the service that runs the spark job
-
STS: Security Token Service, the token system that allows a user or role to assume another role or temporary credentials to access a service
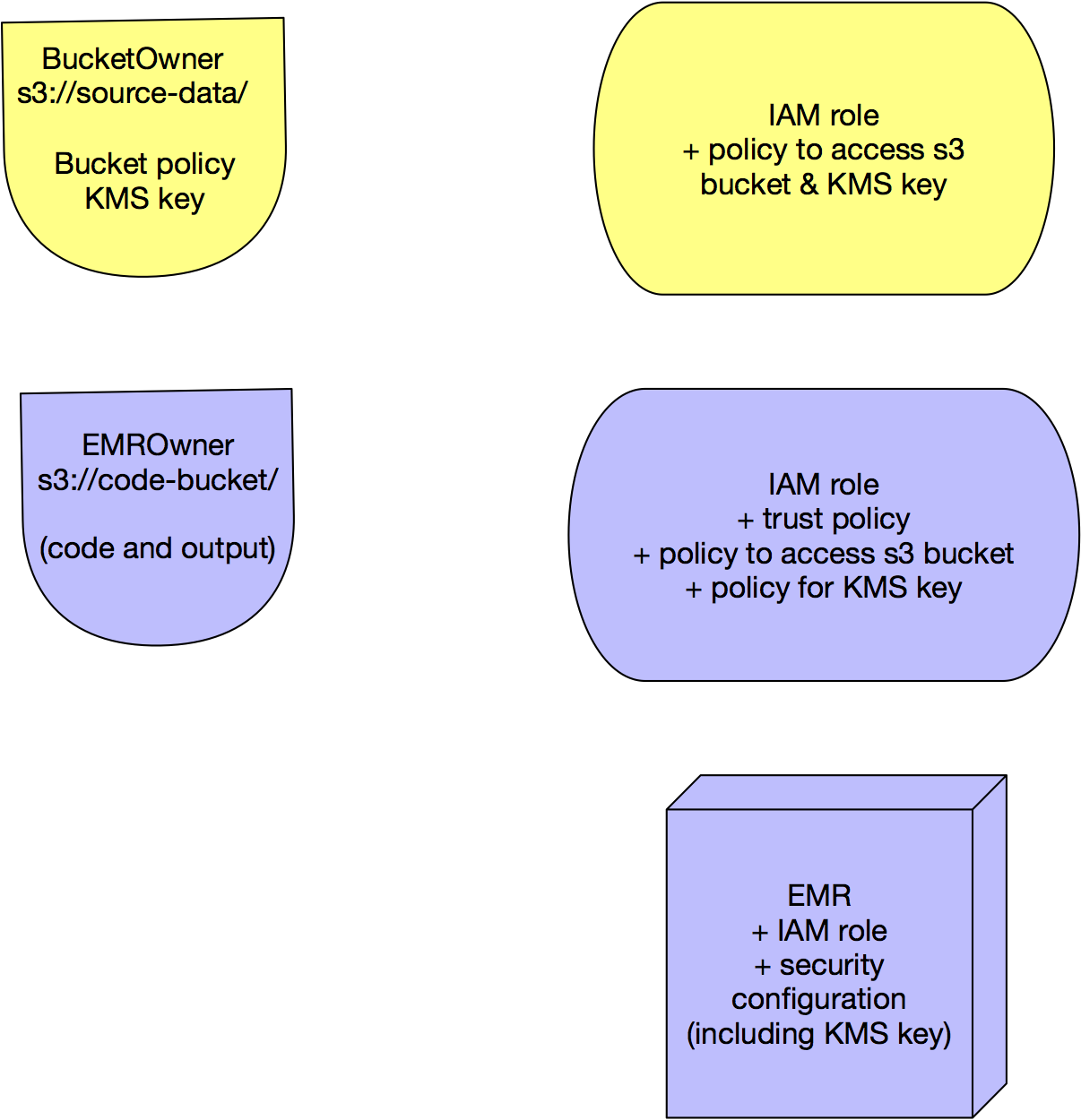
Accounts used:
-
BucketOwner account
-
EMROwner account
Local configuration: I already knew how to configure my local machine to let me have multiple profiles, but if you haven’t done this before, here’s the TL;DR:
On my local machine, I have separate profiles I’m using to access the s3 bucket directly on the BucketOwner account, and to launch the script that starts the EMR cluster and runs the spark job from the EMROwner account.
.aws/config
Profiles are for parameters, in this case mostly just needed for the region information, and I need one for each account because they’re in different regions.
.aws/credentials
When AWS says credentials they mean AWS access keys and secret keys, and they’re specific to the account, so you need one set for each.
Note: if you have no region in one of these accounts, it will fall back to whatever region you had in your default profile, and that will cause all kinds of weird errors, none of which say that you’re in the wrong region.
Configuring the S3 buckets:
- s3://source-data
This bucket is encrypted with a kms key because it includes GDPR-protected information.
arn:aws:kms:us-west-2:111111111:alias/source-data-key
Bucket policy: grants access to both root accounts
{
"Version": "2012-10-17", "Statement": [
{
"Sid": "Example permissions",
"Effect": "Allow",
"Principal": {
"AWS": [ "arn:aws:iam::11111111:root",
"arn:aws:iam::22222222:root"
]
},
"Action": [ "s3:List*",
"s3:Get*" ],
"Resource": [ "arn:aws:s3:::source-data",
"arn:aws:s3:::source-data/*"
] }
] }
Note that you have to list the bucket and objects separately, one without the slash + asterisk (that’s for the bucket), and one with the slash + asterisk (that’s for the objects in the bucket). I still find this a strange design choice.
I ended up taking the advice from some friends to try using the most general List* and Get* because that way I don’t have to worry if I’m not listing every individual type of permission I might need.
- s3://code-bucket
Owned by the EMRowner account
Where the pyspark code lives, and where the pyspark logs and processed output will end up.
I also added a policy to allow the EMR_EC2_DefaultRole to assume the role I had created that had access to the s3 bucket (see the next section for a lot more about IAM roles).
So I got that far and I was able to launch my cluster as usual, but I was getting an Access Denied (403) error on EMR, or an error saying that the EMR_EC2_DefaultRole can’t assume the role I created which has access to the s3 bucket.
Note that there are many reasons you can get a 403 error. I don’t understand why they are unwilling to disclose which aspect of your configuration is wrong, except for their security paranoia. I still think they should give categories of errors to give you some idea of how to troubleshoot.
So I had to backtrack a lot to get a better understanding of how IAM roles actually work.
IAM roles:
Based on my reading, I reasoned that I could create a role with access to the bucket, and assume it from the other account. This seemed like a reasonable approach, although I wasn’t exactly sure about all the nuances of how it worked.
IAM roles can’t actually be layered.
“The policies that are attached to the credentials that made
the original call to AssumeRole are not evaluated by AWS
when making the "allow" or "deny" authorization decision.
The user temporarily gives up its original permissions
in favor of the permissions assigned by the assumed role.“
But, IAM roles can be chained:
"Role chaining occurs when you use a role to assume a second role
through the AWS CLI or API. To engage in role chaining, you
can use RoleA's short-term credentials to assume RoleB."
After going in circles for a while trying to do everything with the AWS CLI, I decided to go back to writing unit tests so I could more easily keep track of what was working and what wasn’t.
First, I wanted to confirm that I could at least list the bucket from the EMROwner account, from my machine:
def test_myEMROwner_profile_can_list_s3_bucket(self):
session = boto3.Session(profile_name = 'EMROwner')
s3_client = session.client('s3')
response = s3_client.list_objects(Bucket = 'source-data')
assert isinstance (response, dict)Next, I wanted to make sure I could assume the new roles I had created, and use those to list the bucket, from my machine:
def role_arn_to_session(profile_name,
region_name= 'us-west-2',
RoleArn= 'arn:aws:iam::1111111:role/emr-s3-access',
RoleSessionName= 'test'):
"""
modified slightly from the example here:
https://gist.github.com/gene1wood/938ff578fbe57cf894a105b4107702de
For assuming a role to use temporary credentials via the AWS STS (security token service).
All params are required
: param profile_name: str, must match a profile in your .aws config
: param region_name: str, not strictly required but strongly recommended : param RoleArn: standard AWS ARN format
: param RoleSessionName: can be any string (required)
: returns : a boto3 Session. Note that temporary credentials expire in 1 hour by default
"""
session = boto3.Session(profile_name = profile_name, region_name =region_name)
client = session.client('sts')
response = client.assume_role( RoleArn = RoleArn, RoleSessionName =RoleSessionName)
return boto3.Session(
aws_access_key_id =response[ 'Credentials' ][ 'AccessKeyId' ],
aws_secret_access_key =response[ 'Credentials' ][ 'SecretAccessKey' ],
aws_session_token =response[ 'Credentials' ][ 'SessionToken' ]) If you’ve done much with s3, you might already know that just because you can list a bucket, doesn’t mean you can get the objects in it, or read them. So I wrote a test for that.
def test_get_object(self):
assumed_session = role_arn_to_session(RoleArn = 'arn:aws:iam::11111111:role/emr-s3-access')
assumed_client = assumed_session.client('s3')
response = assumed_client.get_object(Bucket = 'source-data',
Key = 'example-filename.gz')
assert response['ResponseMetadata'][ 'HTTPStatusCode' ] == 200
I also needed to make sure I could actually access the key:
def test_describe_key( self ):
kms_client = self .session.client( 'kms' )
response = kms_client.describe_key( KeyId = 'arn:aws:kms:us-west-2:1111111:alias/a-uuid' )
assert response['KeyMetadata'][ 'KeyUsage' ] == 'ENCRYPT_DECRYPT'
In the end, I created a new IAM role, let’s call it arn:aws:iam::2222222:role/emr-s3-bucket-role, to use as the JobFlowRole in my pyspark configuration.
This role has 3 policies:
-
AmazonElasticMapReduceforEC2Role (you don’t have to create this one, you just have to add it to the role)
-
Allow-assume-s3-role (had to create this one)
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "arn:aws:iam::11111111:role/EMR-access-s3" } } -
Allow-kms-use (also had to create this one)
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "kms:*", "Resource": "*" } ] }
And I also had to create this trust policy:
- arn:aws:iam::2222222:user/szeitlin (me, so I can assume it)
- The identity provider(s) ec2.amazonaws.com (so EMR can assume it)
Great! That seems like a lot of stuff already. That’s probably enough, right?
Wrong. Still getting 403 errors. What else do I need?
I contacted AWS support and they said the problem is that you can’t use a default KMS key with cross-account access (this is documented in one place, but it’s really not made obvious when you’re choosing which keys to use).
I was finding that if I logged into my EC2 instance from a failed EMR job, I could not copy file 00.log.gz from 2018/06/06/ encrypted with the default key: arn:aws:kms:us-west-2:1111111:key/e-uuid
And I could copy, but not read, file 01.log.gz from 2018/06/06 encrypted with the custom key: arn:aws:kms:us-west-2:11111111:key/a-uuid
So that clearly wasn’t the whole story.
EMR Instance Profile:
The Instance Profile is a special thing on EC2. It’s basically a container for the IAM role credentials, which you use to get temporary credentials from the EC2 instance metadata service, so that your code can access the other AWS services.
The AWS tech support people suggested I should follow these instructions:
https://aws.amazon.com/blogs/big-data/securely-analyze-data-from-another-aws-account-with-emrfs/
- Create IAM Roles on both accounts (I had already done that)
- Implement a custom credential provider in java.
I wrote them back and said java? really?
And while I was waiting for a response, I went ahead and implemented a way to assume my IAM roles explicitly from inside my spark job, just to see if that would work.
I decided to try using this (from here: https://github.com/boto/boto3/issues/222)
with a modified version of the code I already had:
from botocore.credentials import InstanceMetadataProvider, InstanceMetadataFetcher
provider = InstanceMetadataProvider( iam_role_fetcher = InstanceMetadataFetcher( timeout = 1000 ,
num_attempts = 2 ))
creds = provider.load()
access_key = creds.access_key
secret_key = creds.secret_keyThen use the same code from before for assuming a role, but this time you’re telling the EC2 Instance Profile to assume the IAM role that has the s3 bucket access
Plus this, so the hadoop user could use the new credentials:
sc._jsc.hadoopConfiguration().set( 'fs.s3a.access.key' , creds[ 'access_key_id' ])
sc._jsc.hadoopConfiguration().set( 'fs.s3a.secret.key' , creds[ 'secret_key' ])
sc._jsc.hadoopConfiguration().set( 'fs.s3a.session.token' , creds[ 'session_token' ])But I was still getting the same AccessDenied 403 error.
AWS finally wrote me back and said I didn’t need a custom credential provider, I should instead just try using SSE-KMS in the security configuration for the EMR cluster.
I had already tried setting up the security configuration for the EMR cluster, but by this point, the logic of AWS was finally starting to sink in, even though much of their documentation lacks explicit explanations of why you have to do a thing a specific way:
You can’t go down in security level.
So since I had encryption on the source s3 bucket, that meant I had to enable the same encryption on the EMR filesystem (EMRFS), whether I cared about that or not (at this point, I did not care).
The security configuration, in case you’ve never used it, is something you can set up via this obscure tab on the side of the EMR service window (or via the CLI).
I tried it first with the EMR_EC2_DefaultRole and it gave me an error about not being able to assume itself. This seems like a bug to me, since the permissions on that role were identical to the one that ultimately worked.
Note that you can’t edit a security configuration, you can only delete and/or create a new one. So I started over and created a new one with the identical permissions and a different name.
Finally, it worked for the ones with the custom key. (Totally anticlimactic, btw, after all that confusion.)
And then, in case you’re like me and didn’t know this, it turns out that the only way to change the encryption key on s3 is to re-upload, or copy, the files over again. So the CLI command looks like this:
aws s3 cp s3://source-data/00.log.gz s3://source-data/00.log.gz
--sse aws:kms --sse-kms-key-id arn:aws:kms:us-west-2:11111111:alias/a-uuid --profile BucketOwner
And the boto3 code for that looks something like this:
def re_encrypt_objects(datestring, keyid= 'arn:aws:kms:us-west-2:111111111:alias/a-uuid' ):
'''
: param datestring: str, format 'YYYY/MM/DD'
: param keyid: str
'''
for item in list_of_objects:
copy_source = { 'Bucket' : bucketname,
'Key' : objectname}
s3.meta.client.copy(copy_source, copy_source[ 'Bucket' ], copy_source[ 'Key' ],
ExtraArgs ={ 'ServerSideEncryption' : 'aws:kms' ,
'SSEKMSKeyId' :keyid})
logging.info( 're-encrypting {}' .format(item))Overall, I’d say I have one major suggestion for AWS: give us some easier ways to tell which parts of our configurations are working correctly. Sure, you don’t want to give us too many hints if it’s a security risk, I can almost understand that (almost). But almost all of your documentation gives advice on how to do something, with zero advice on how to check if that step succeeded. It’s like writing code with no tests: a recipe for headaches.